Method
Pipeline Overview
OpenBox is a two-stage automatic annotation pipeline that leverages 2D vision foundation models. In the first stage, Cross-modal Instance Alignment associates instance-level cues from 2D images with the corresponding 3D point clouds. In the second stage, Adaptive 3D Bounding Box Generation categorizes instances by rigidity and motion state, then generates adaptive bounding boxes with class-specific size statistics.
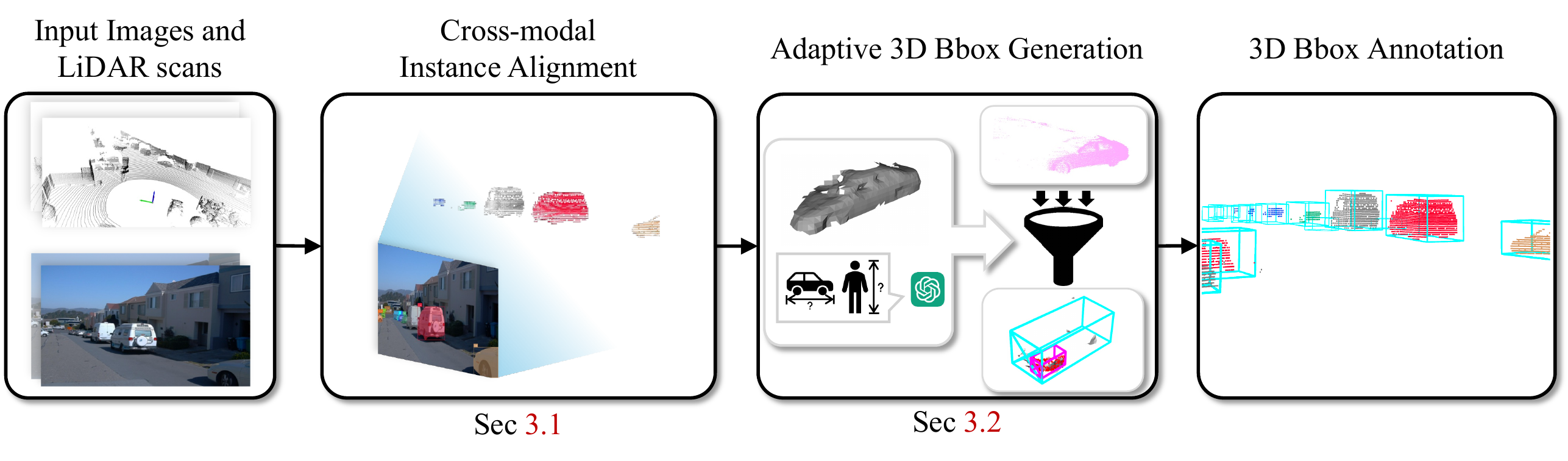
Figure 1. Overview of the OpenBox pipeline. Left: Cross-modal instance alignment (Stage 1). Right: Adaptive bounding box generation (Stage 2).
Stage 1: Cross-modal Instance Alignment
The pipeline maps 2D image information to 3D point clouds using vision foundation models. Grounding DINO generates 2D detections and SAM2 refines them into precise instance masks. These masks are unprojected onto the point cloud using camera calibration. In parallel, HDBSCAN clustering on ground-removed LiDAR produces coarse 3D clusters. Context-aware refinement then fuses both proposals, discarding noisy points and incorporating adjacent point cloud cluster points for refined per-object point clouds.
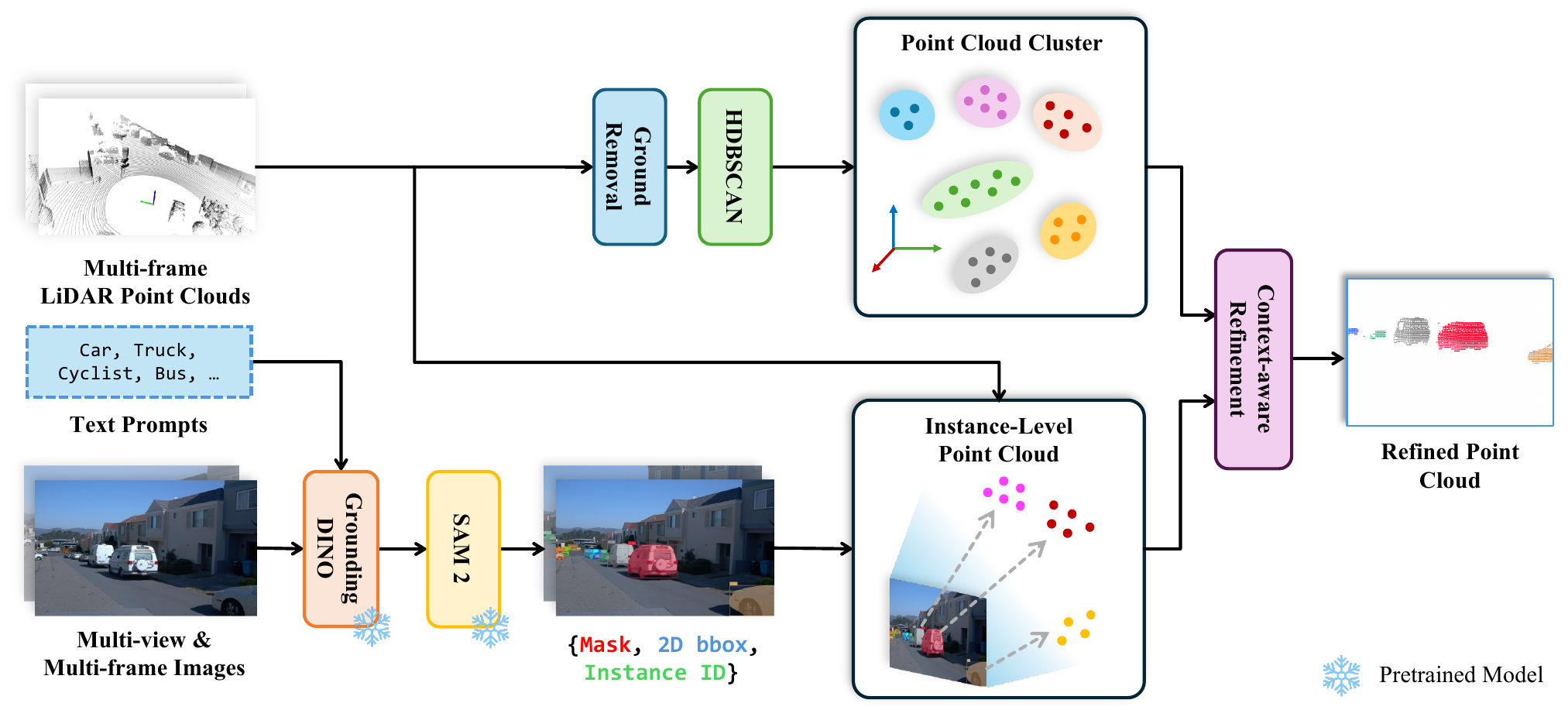
Figure 2. Cross-modal instance alignment. Upper: HDBSCAN clustering on ground-removed LiDAR. Lower: Grounding DINO detections followed by SAM2 segmentation. Context-aware refinement fuses both proposals for refined per-object point clouds.
Context-aware Refinement
To address noisy point clouds caused by LiDAR projections onto occluding background objects, the method performs majority voting across clustered regions obtained via HDBSCAN. For each cluster, bidirectional proximity-based inclusion ratios determine whether clusters overlap sufficiently with instance-level point clouds. Clusters meeting overlap thresholds receive instance IDs and are retained; others are discarded.

Figure 3. Context-aware refinement. (a) Reference image. (b) Point cloud clusters after HDBSCAN on ground-removed LiDAR. (c) Noisy instance-level point clouds from mask unprojection. (d) Refined point clouds after context-aware refinement.
Stage 2: Adaptive Bounding Box Generation
Instances are categorized into three physical types: rigid-static, rigid-dynamic, and deformable. For static-rigid instances, surface-aware filtering suppresses noise through proximity voting on reconstructed mesh vertices using Signed Distance Functions (SDF). Surface normal vectors then determine resizing directions for bounding box refinement, and final box selection compares 3D candidates against 2D bounding boxes through 2D IoU alignment across multiple views.
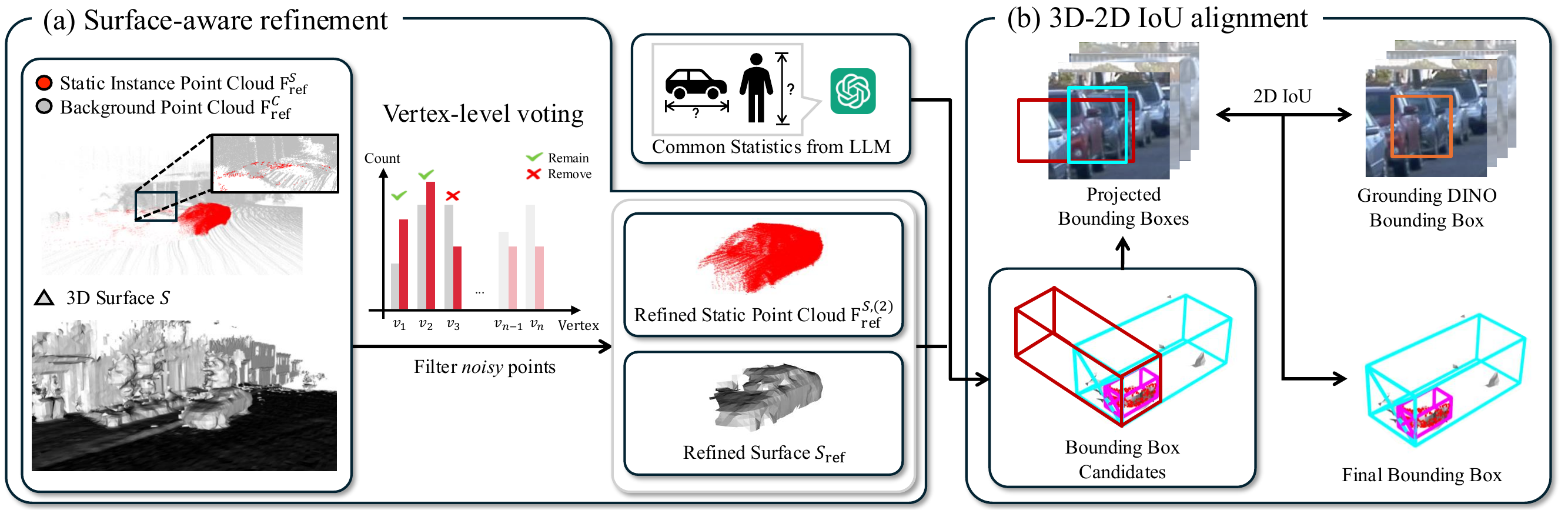
Figure 4. Static-rigid instance handling. (a) Vertex-level voting on reconstructed SDF surface filters noisy points. (b) Surface normal vectors guide bounding box size adjustments; final box selection uses 2D IoU alignment.
Dynamic Instance Box Extension
For dynamic-rigid instances, object orientation is aligned with position differences across adjacent frames using 2D tracking IDs. After orientation alignment, box size refinement uses dot products between surface normals and LiDAR ray directions. Boxes extend only when these dot products are negative, indicating unobserved surfaces. Final sizes are determined by statistical priors.
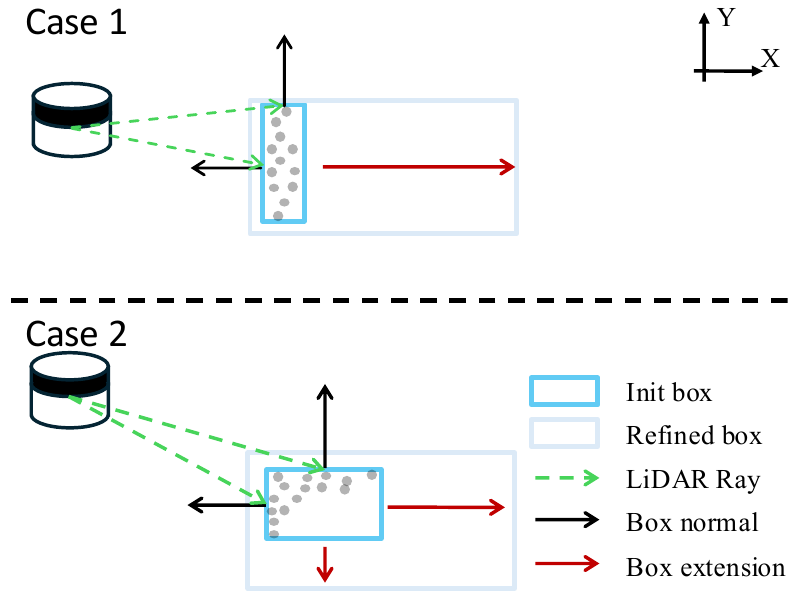
Figure 5. Visibility-based box extension for dynamic instances. Case 1: Single negative dot product yields one-sided extension. Case 2: Two negative values produce two-sided box extension.
Qualitative Results
Annotation Comparison on Waymo Open Dataset
Qualitative comparison of automatically generated bounding boxes (blue) against human annotations (red) on the Waymo Open Dataset training set. OpenBox recognizes static instances that baselines miss (Region A: static travel trailer), successfully detects objects in challenging scenarios like garage interiors with sparse points (Region B), and achieves improved localization accuracy for opposite-lane vehicles (Region C).
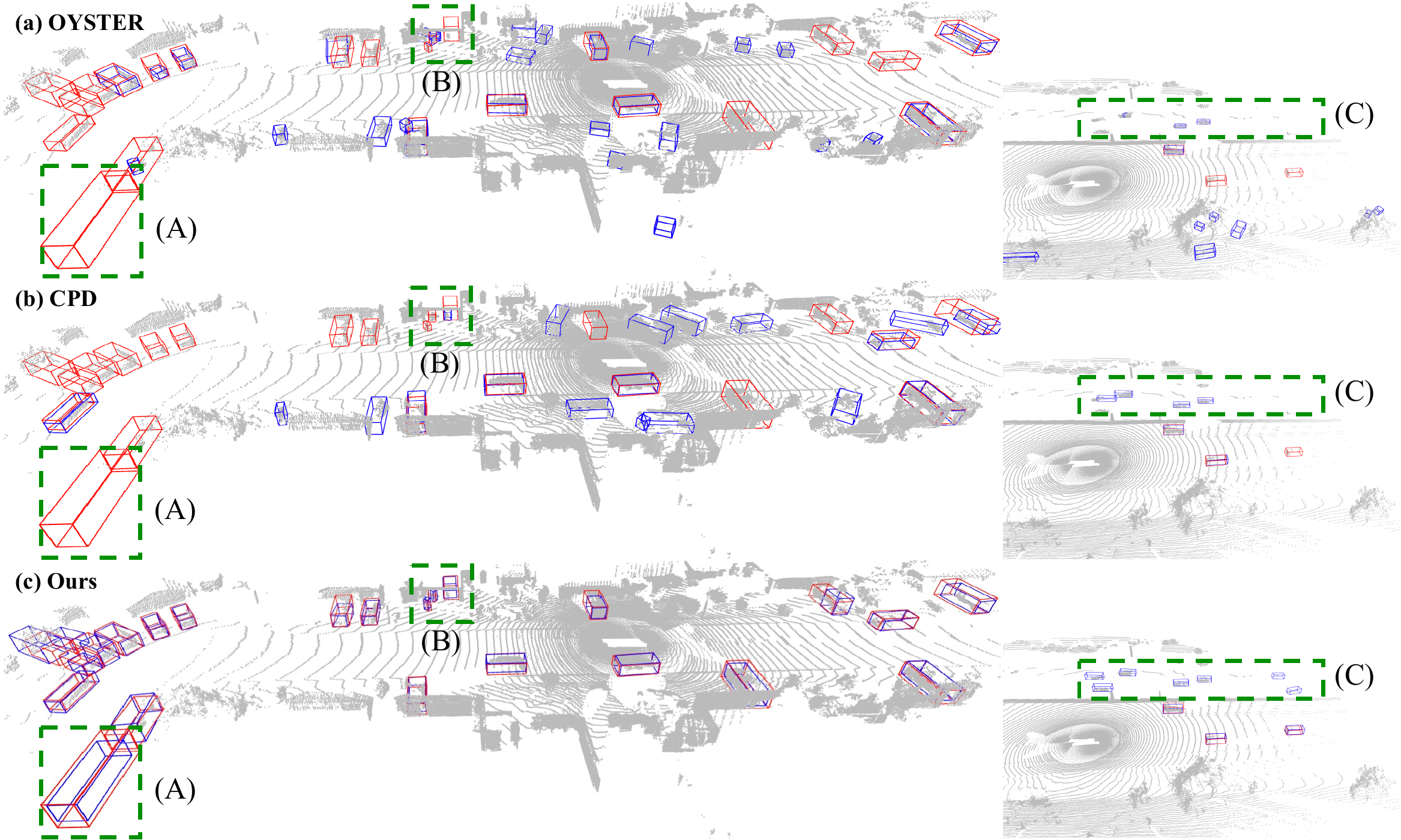
Figure 6. Qualitative annotation comparison on Waymo Open Dataset training set. Blue: automatically generated boxes. Red: human annotations.
Open-vocabulary Annotation
OpenBox enables open-vocabulary detection of object categories beyond standard dataset classes, which is essential for real-world autonomous driving scenarios. The figure demonstrates automatic 3D bounding box annotation for novel object classes such as strollers, fire hydrants, and dogs.

Figure 7. Open-vocabulary annotation results. Red point clouds and cyan bounding boxes show detected novel object classes (strollers, fire hydrants, dogs).
BibTeX
@inproceedings{Lee_OpenBox_NeurIPS_2025,
author = {In-Jae Lee and Mungyeom Kim and Kwonyoung Ryu, Pierre Musacchio and Jaesik Park},
title = {OpenBox: Annotate Any Bounding Boxes in 3D},
journal = {NeurIPS},
year = {2025},
}